Learning Blind Humanoid Locomotion
Learning humanoid locomotion in complex terrain using disentangled world model learning.
Project Overview
This project studies a humanoid robot walking stably over complex terrains such as stairs, slopes, and uneven or fragmented ground by combining a world model with policy learning.
 Fig 1. Simulation of the humanoid robot traversing complex terrains
Fig 1. Simulation of the humanoid robot traversing complex terrains
Key Methodology: Disentangled World Model Learning
The core idea of this research is to learn a disentangled latent representation that separates intrinsic states related to robot dynamics from extrinsic states describing terrain and contact conditions, using sensor observation histories.
By disentangling these states, the robot can effectively distinguish between its own body dynamics and external environmental factors, leading to more robust locomotion.
Model Architecture
The proposed architecture utilizes a single encoder that maps observation histories to latent variables. These variables are processed as follows:
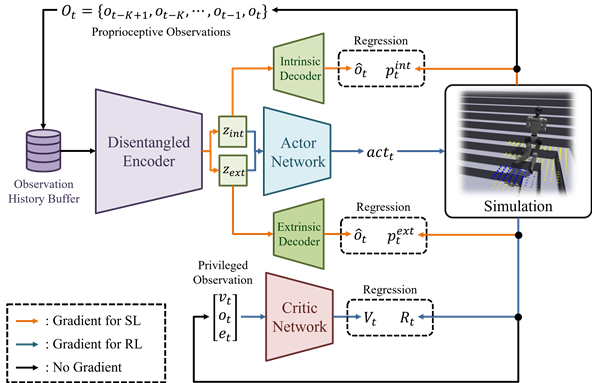 Fig 2. Model Architecture
Fig 2. Model Architecture
- Latent Splitting: The latent variables are split into intrinsic and extrinsic components.
- Policy Learning: These components are fed into an actor-critic walking policy trained with PPO (Proximal Policy Optimization) and auxiliary reconstruction losses.
- Regularization: The methodology designs regularization terms to enforce separation between intrinsic and extrinsic latents.
- Time-Biased Queries: The model leverages time-biased queries to emphasize important moments in the history.
Acknowledgement
This research was supported by the Korea Institute of Machinery and Materials (KIMM).