Learning RoboSumo for quadruped robots
Self-play reinforcement learning for RoboSumo.
Duration: 2023.09 - 2023.12
Project Overview
This project explores the application of Self-Play Reinforcement Learning to control a quadruped robot in a competitive environment known as RoboSumo. The objective is to train a policy that can push an opponent out of a ring while maintaining its own balance within the arena.
In competitive scenarios like RoboSumo, the opponent’s strategy is often unpredictable. Standard Multi-Agent Reinforcement Learning (MARL) approaches may struggle to adapt to diverse or unseen behaviors. To address this, we implemented a self-play strategy where the agent learns by competing against copies of itself, progressively improving its skills.
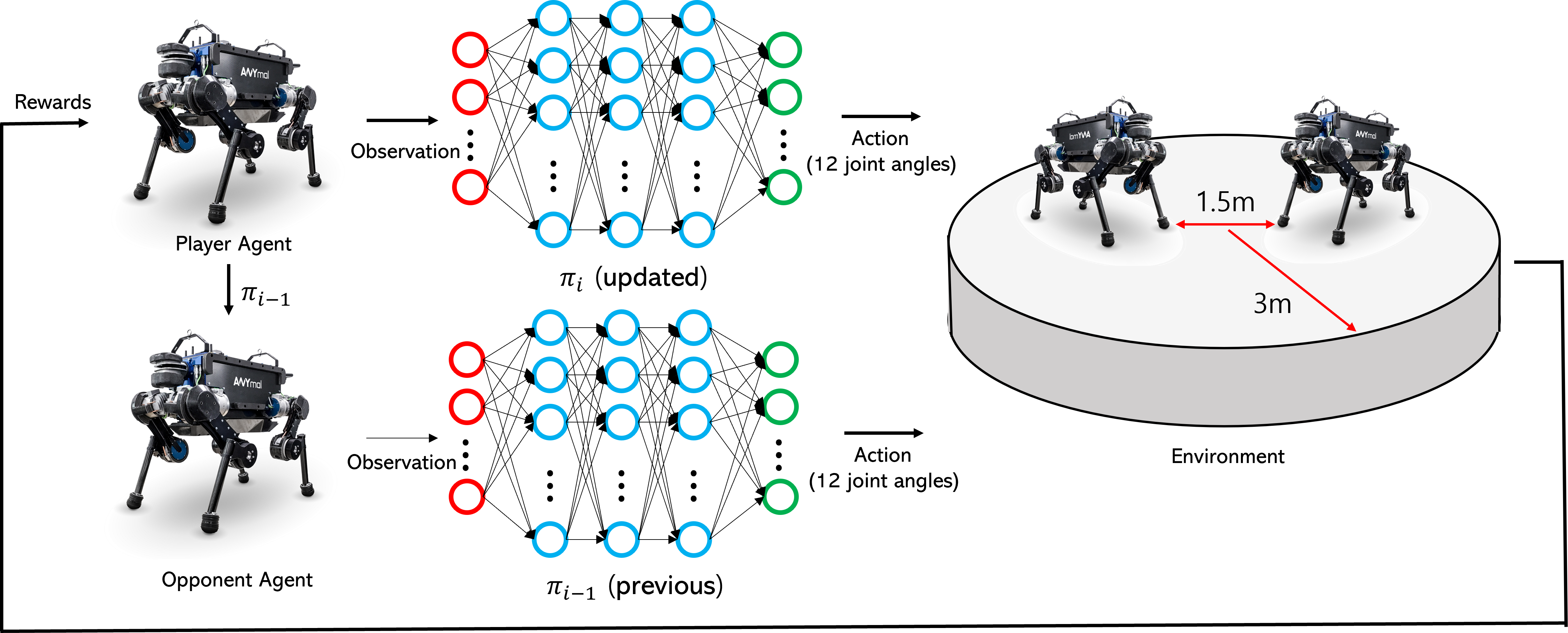 Fig 1. Overview of the RoboSumo competition
Fig 1. Overview of the RoboSumo competition
Methodology
1. Simulation Environment
The training was conducted in a physics simulation environment (Isaac Gym) designed for high-performance robot learning. The setup includes two quadruped robots placed in a circular arena.
2. Self-Play Training
- Algorithm: We utilized PPO (Proximal Policy Optimization) for policy optimization.
- Curriculum: The agent starts by playing against a random policy and gradually transitions to playing against recent versions of itself. This ensures that the opponent’s difficulty scales with the agent’s capability, preventing the learning process from stagnating.
3. Reward Design
The reward function was carefully designed to encourage aggressive yet stable behaviors:
- Push Reward: Given for displacing the opponent towards the edge.
- Survival Reward: Given for staying within the ring.
- Stability Penalties: Penalties for falling or unstable body orientation.
Results
The self-play agent was evaluated against baseline policies (e.g., random agents or standard RL agents trained without self-play). The results demonstrated that the agent trained with self-play developed robust strategies to counter various opponent moves, achieving a significantly higher win rate compared to non-self-play baselines.
Acknowledgement
This project was conducted as a term project for the ME491 Learning Based Control course at KAIST.